My AI knows my entire job. Yours should too.
My AI knows my entire job. Yours should too.
Every email, meeting, document and chat thread I have, mirrored into an AI partner that runs on my laptop — the knowledge base never leaves my machine. It absorbed the work I never needed to be doing myself. Here’s the architecture, so you can build yours.
The context gap
Someone, somewhere, is estimating how much of your job an AI could do. The wrong response is hoping they get it wrong. The right response is finding out first — by building it yourself.
So I did.
Here’s what those estimates always miss: intelligence was never the bottleneck. Frontier models are already smart enough for most of what fills a workday. What they lack is context. ChatGPT can write you a sonnet, but it doesn’t know what you agreed in yesterday’s standup. It can’t — everything that defines your actual job lives scattered across SaaS silos: documents (Drive, SharePoint), wiki pages (Confluence, Notion), email, calendar, team chat (Slack, Teams, Mattermost) — and the notes of every meeting you’ve ever sat through. And your AI can see none of it.
The difference between an AI you chat with and an AI you work with isn’t intelligence. It’s context.
So I gave mine everything. Every meeting, every email, every document and chat thread — mirrored every half hour into an AI partner that runs on my laptop and answers with citations. The knowledge base never leaves my machine. The indexing bill is zero.
Not so I could stop working — so I could stop doing the parts of my job I never needed to be doing myself.
What I mean by “AI partner”
First, let me kill the lazy misreading: the goal is not to automate your job, do nothing, and still get paid. That plan fails on contact with reality — if an AI alone can do your job, the AI doesn’t need you in the loop, and sooner or later someone runs that calculation.
The goal is multiplication. The AI absorbs the delegable layer of the job — recall, search, summaries, meeting prep, first drafts, “what did we decide about X three months ago?” — and you keep what was always the actual job: judgment, relationships, architecture, deciding what matters. Output multiplies. The job gets better, not emptier.
There’s a second-order effect worth saying out loud. Your boss can maybe replace an employee with an AI. Replacing the employee who built the AI — and wields it daily — is a much harder trade: you’d be discarding the multiplier to keep one of its factors. The safest seat in the room is upstream of the automation.
So: an AI partner, not a chatbot. Three properties make the difference.
- It knows your full work context. Not a folder you uploaded once — a live, half-hourly mirror of everything: mail, meetings, documents, chats.
- It cites its sources. Every answer points back to the chat message, the wiki page, the email it came from. An assistant that can’t show provenance is a liability, not a partner.
- It operates tools — including, as you’ll see, the very infrastructure that feeds it.
And one property that, for me, is non-negotiable: it runs on my hardware. I’m a solutions architect in the distributed-ledger space; my day job is getting organizations that don’t fully trust each other to act on data they can all verify. (Remember that — it will rhyme.) In that world — or in finance, legal, healthcare — shipping the company’s institutional memory to a third-party “chat with your data” service is a non-starter. Local-first isn’t a preference. It’s the prerequisite that makes the whole idea viable.
Let me draw that boundary precisely, because precision is the point: the corpus, the index and every search stay on my machine. If the agent on top is a cloud model, it sees only the few snippets a given task pulls into its context — never the corpus. Run a local model and not even that leaves.
By the numbers
Before the story, the scale — so we agree this isn’t a toy:
| Knowledge mirrored | 100 GB+ across Drive (documents + meeting notes), Confluence, Email, Calendar, Slack |
| Normalized corpus | 5,900+ Markdown files |
| Search index | 52,000+ chunks in a local vector DB |
| ML stack | 2 × 4B-parameter models (embedding + reranking), CPU-only, ~14 GB RAM |
| Retrieval-stack cost | $0/month — embedding, search and reranking all run locally |
| Code footprint | ~4,000 lines of Python, 12 shell wrappers, one systemd timer |
What it feels like
Three moments from the last few weeks.
Decision archaeology. Mid-call, someone asks why we’d ruled out an approach the room now wants to revisit. I ask the partner: “What did we decide about this, and where?” Before the conversation has moved on, I have the decision, the date, and three citations — the chat thread where it was argued, the wiki page where it was written down, and the meeting note where it was settled. The detail that sold me forever: the answer disagreed with my memory. It was right. It had receipts.
Meeting prep. “Brief me for my 14:00.” It pulls the invite, the email chain that caused the meeting, the open action items from the last call, and the attached deck everyone will pretend to have read. By the time I’ve refilled my coffee, the brief is waiting — and I walk in as the only prepared person in the room.
Prior art. Writing a proposal, I ask: “Find everything we’ve ever produced about supply-chain data sharing — decks, estimates, old proposals.” Out of 100 GB+ of Drive it surfaces three relevant decks, a pricing spreadsheet, and a two-year-old proposal nobody on the current team remembers existed. Two of those five documents I had never seen at all.
None of this is a parlor trick. It’s one trick — retrieval with provenance — applied to the only corpus that matters: yours.
The architecture
%%{init: {
"theme": "base",
"themeVariables": {
"fontFamily": "Helvetica, Arial, sans-serif",
"fontSize": "14px",
"primaryTextColor": "#1e293b",
"lineColor": "#64748b",
"clusterBkg": "#fafafa",
"clusterBorder": "#e2e8f0",
"edgeLabelBackground": "#ffffff"
},
"flowchart": { "curve": "basis", "nodeSpacing": 35, "rankSpacing": 50 }
}}%%
flowchart TB
subgraph silos["Where your work actually lives"]
direction LR
MT["Meeting notes"] -. auto-saved .-> GD["Cloud docs<br/>(Drive, SharePoint)"]
CF["Wiki<br/>(Confluence, Notion)"]
EM["Email"]
CAL["Calendar"]
SL["Team chat<br/>(Slack, Teams)"]
end
subgraph sync["Sync orchestrator — one systemd timer, every 30 min, fault-isolated"]
ORCH["one-way incremental mirror<br/>rclone · CQL · History API · syncTokens · checkpoints"]
end
subgraph ragstack["Local RAG stack — Docker, CPU-only, loopback-only, ~14 GB RAM"]
direction LR
CHUNK["section-aware chunker<br/>content-hash incremental"] --> EMB["embedder<br/>Qwen3-Embedding-4B<br/>llama.cpp"] --> QD[("Qdrant<br/>52k vectors + metadata")]
RR["reranker<br/>Qwen3-Reranker-4B<br/>cross-encoder"]
end
subgraph agent["The AI partner"]
MCP["MCP server — one search tool<br/>stdio + streamable HTTP"]
CC["Claude Code / any MCP client<br/>persistent memory + runbook"]
end
GD & CF & EM & CAL & SL --> ORCH
ORCH --> MIRROR[("Markdown mirror — 5,900+ files<br/>one atomic git commit per cycle")]
MIRROR -- binaries --> DOCL["docling<br/>PDF · DOCX · XLSX · PPTX<br/>→ Markdown"]
DOCL -- Markdown --> MIRROR
MIRROR --> CHUNK
QD -. top-50 candidates .-> RR
RR -- top-10 reranked --> MCP
QD -. fallback: vector scores .-> MCP
MCP <--> CC
MIRROR -. direct file access .-> CC
classDef source fill:#dbeafe,stroke:#2563eb,stroke-width:1.5px,color:#1e293b
classDef pipe fill:#fef9c3,stroke:#ca8a04,stroke-width:1.5px,color:#1e293b
classDef store fill:#e2e8f0,stroke:#475569,stroke-width:1.5px,color:#1e293b
classDef model fill:#ede9fe,stroke:#7c3aed,stroke-width:1.5px,color:#1e293b
classDef agentnode fill:#dcfce7,stroke:#16a34a,stroke-width:1.5px,color:#1e293b
class MT,GD,CF,EM,CAL,SL source
class ORCH,DOCL,CHUNK pipe
class MIRROR,QD store
class EMB,RR model
class MCP,CC agentnode
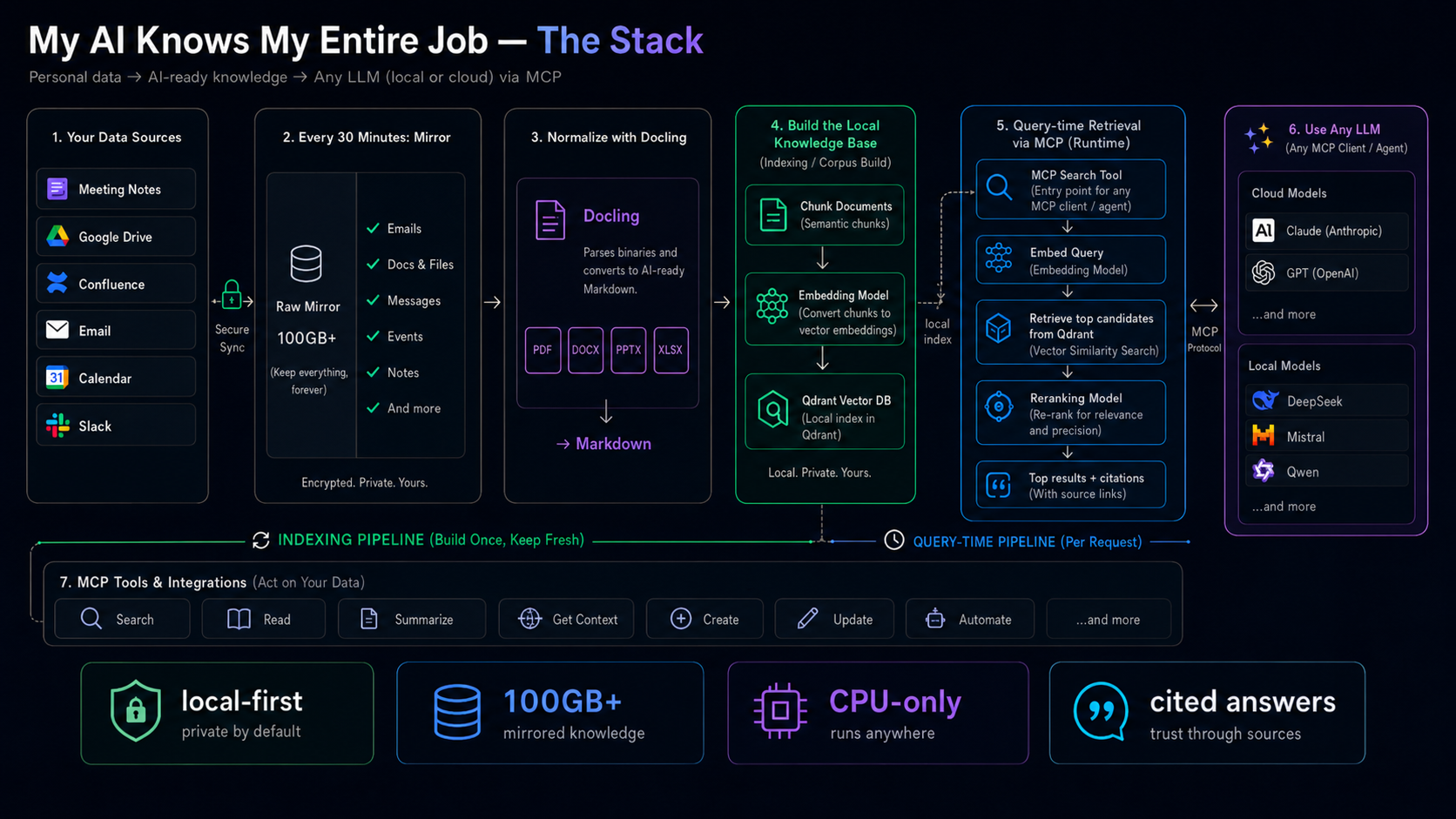
The system is a pipeline that turns a half-dozen scattered sources into one queryable, citable brain. Top to bottom:
Mirror. One orchestrator, one systemd timer, every 30 minutes through the workday. Each source syncs through its API’s native incremental idiom — rclone for Drive, CQL lastModified queries for Confluence, email via Gmail’s History API, Calendar syncTokens, per-conversation timestamp checkpoints for Slack. Meeting notes need no syncer of their own: the meeting assistant auto-saves its notes into Drive, and they ride the same mirror. Steps run sequentially and are fault-isolated: Slack being down doesn’t cost me email. The one slow step — the full Drive walk — self-throttles to once a day; everything else refreshes every half hour. And the whole thing is one-way by construction: upstream → local, with no code path that writes back into company systems.
Normalize. Everything becomes Markdown. Pages, threads and events convert directly; binaries — PDF, DOCX, PPTX, XLSX — go through docling with accurate-table mode and formula enrichment. Any conversion that balloons past 200 KB of Markdown (in practice: a huge spreadsheet of dense tables) is replaced by a small reference stub — still findable by name and metadata, but not allowed to bloat the index for near-zero retrieval value. Markdown is the universal interface: greppable, diffable, and native to every model and tool I’ll ever point at it.
Snapshot. After each cycle, the orchestrator makes exactly one git commit of the entire mirror — sources and their converted Markdown counterparts land atomically, together. Every cycle produces a content-addressed snapshot of “everything I knew at time T”. Hold that thought for the blockchain section.
Index. Markdown gets chunked along its section structure (## headings, capped at 2,000 tokens), embedded by Qwen3-Embedding-4B served by llama.cpp on CPU (why llama.cpp), and upserted into Qdrant with its metadata: source, channel, author, date, title, upstream URL. Indexing is incremental by content hash, not just modification time — a file rewritten with identical bytes costs nothing. Edits replace their chunks; deletions purge them.
Serve. A single tool exposed over MCP, the Model Context Protocol: search(query, source?, channel?, author?, date_from?, date_to?, k). MCP is what makes the stack future-proof — any compliant agent can call the tool. Claude Code attaches over stdio on my machine; anything remote uses streamable HTTP. One tool, any agent, including whatever replaces today’s agents.
Agent. The partner itself. It uses retrieval for recall and the filesystem for precision — when a chunk looks relevant, it opens the underlying document and reads the whole thing, because the mirror is just files on disk. That combination matters: RAG finds the needle; the file gives you the haystack back.
Anatomy of a query
%%{init: {
"theme": "base",
"themeVariables": {
"fontFamily": "Helvetica, Arial, sans-serif",
"fontSize": "14px",
"actorBkg": "#dbeafe",
"actorBorder": "#2563eb",
"actorTextColor": "#1e293b",
"signalColor": "#334155",
"signalTextColor": "#334155",
"noteBkgColor": "#fef9c3",
"noteBorderColor": "#ca8a04",
"activationBkgColor": "#ede9fe",
"activationBorderColor": "#7c3aed",
"labelBoxBkgColor": "#fafafa",
"labelBoxBorderColor": "#e2e8f0"
},
"sequence": { "mirrorActors": false, "actorMargin": 40, "messageMargin": 32 }
}}%%
sequenceDiagram
autonumber
actor U as You
participant A as Agent
participant M as Search tool<br/>(MCP)
participant E as Embedder<br/>Qwen3-Embedding-4B
participant Q as Qdrant
participant R as Reranker<br/>Qwen3-Reranker-4B
U->>A: "What did we decide about X?"
A->>+M: search(query, filters)
rect rgb(239, 246, 255)
note right of M: Stage 1 — recall (fast, lossy)
M->>+E: embed(instruction-prefixed query)
E-->>-M: query vector
M->>+Q: top-50 nearest, metadata-filtered
Q-->>-M: candidate chunks
end
rect rgb(245, 243, 255)
note right of M: Stage 2 — precision (slow, exact)
M->>+R: cross-encode query × 50 passages
note over R: 30–60 s on CPU
R-->>-M: relevance scores
end
M-->>-A: top-10 chunks + paths/URLs
A-->>U: grounded answer, with citations
Why two models? Because embeddings are fast and lossy, while cross-encoders are slow and precise. A bi-encoder compresses each passage into a single vector ahead of time — ideal for scanning 52,000 chunks in milliseconds, but it can never weigh the query against a passage word by word. So retrieval runs in two stages: the vector index proposes the top 50 candidates, then Qwen3-Reranker-4B reads each candidate together with the query and re-scores it. The top 10 survive, citations attached. One refinement worth stealing: Qwen3 embeddings are asymmetric — documents are embedded raw, queries get an instruction prefix describing the retrieval task. Measurably better recall, and it requires no re-indexing.
Honesty about cost: cross-encoding 50 passages through a 4-billion-parameter model on a CPU takes 30–60 seconds. For an agent that fires a search and keeps working while results arrive, that’s fine. For interactive autocomplete it would be disqualifying. Know which product you’re building. And if the reranker ever fails, the tool degrades gracefully to vector-ranked results — the slow precise brain switches off, the fast lossy one keeps answering.
Engineering notes from the trenches
The diagram is the easy part. These are the things that made it actually work — the lessons tutorials don’t teach.
Five APIs, five dialects of “incremental”
Nobody gives you “sync me everything new” for free. Every source earns incrementality in its own dialect:
| Source | The idiom |
|---|---|
| Google Drive | rclone one-way sync, self-throttled to daily |
| Confluence | CQL lastModified >= queries |
| Gmail’s History API on top of a one-time bootstrap | |
| Calendar | syncToken per calendar |
| Slack | per-conversation timestamp checkpoints |
One detail I’m fond of: Slack syncs DMs first, then private channels, then public ones — so when rate limits bite, they degrade the least personal content first.
The 13-hour hang
I closed my laptop mid-index. The embedding container came back from suspend wedged; the indexer sat on a dead socket until I found it the next morning, 13 hours later. Servers don’t have lids — this is a failure mode laptop-grade infrastructure has and cloud playbooks never mention. The fix is boring and absolute: a preflight that brings the stack up and verifies the embedder’s /health before indexing starts — fail fast, never hang — plus small embedding batches and retry-with-reconnect. Now a suspend pauses the run instead of killing it.
The reranker that scored everything zero
The first reranker model file I deployed loaded fine, ran fine, and scored every passage near zero. The community Q8 quantization was missing its classification head tensor — the model literally could not produce a relevance score, and nothing errored. The F16 conversion, built with the proper conversion script, works. Lesson burned in: in local-AI land, model files are a supply chain. A checksum proves the file you downloaded is the file they uploaded — not that the file they uploaded is correct. Verify outputs, not just provenance.
Re-embedding nothing, every cycle
Calendar and Confluence rewrite their Markdown every sync — fresh export, identical bytes, new modification time. Naive mtime invalidation would re-embed thousands of chunks every cycle for nothing, on CPU, forever. The fix: the indexer’s state stores {mtime, content-hash} per file. An unchanged mtime skips instantly; a changed mtime triggers a hash check; only actually-changed bytes re-embed. A microsecond hash comparison buys back hours of compute a day.
The Word comment that killed a pipeline
A .docx exported from Google Docs can contain comments missing the w:author attribute the OOXML spec requires — and that one absent attribute aborts the converter’s entire DOCX backend. The fix: detect the failure, inject an empty author into a temporary copy, retry once. Real-world documents are hostile input; a document pipeline without a repair-and-retry path is a pipeline that stops weekly.
Guardrails you only notice when they fire
The sync service runs under a cgroup memory ceiling, so a heavy document conversion can kill itself without taking down the desktop. Dependencies update in two tiers: everything safe auto-updates every run; inference images, model files and the vector DB are deliberately pinned, because a silent model swap invalidates 52,000 embeddings. And the inference flags are load-bearing — this embedding family needs --pooling last; the rerank endpoint refuses to exist unless --reranking, --pooling rank and --embedding are all present. Each of those was an afternoon of my life.
What still isn’t solved, on purpose: the mirror is strictly one-way (the partner drafts; I send). A few vendor walls stand — some attachment downloads need a full OAuth dance that plain API tokens can’t perform, so for those the mirror keeps rich metadata manifests instead of bytes. And CPU reranking will never be interactive-fast. Trade-offs, chosen consciously.
The blockchain thread
I promised this would rhyme.
My day job is distributed-ledger architecture: getting organizations that don’t fully trust each other to act on a shared, verifiable view of data scattered across their silos. Strip away the consensus machinery and that is exactly what this project is — the single-player version. Same problem shape: fragmented sources, normalized into a mirror trustworthy enough to act on. The multi-party version needs cryptographic trust because the parties are adversarial; the single-player version relaxes that constraint, but the architectural instincts transfer whole.
Some rhymes are structural. The per-cycle git commit means my knowledge mirror is a Merkle DAG — every snapshot content-addressed and hash-linked to its parents, the same data-structure family that underpins every distributed ledger. I didn’t add tamper-evidence to my institutional memory; I inherited it by respecting an old, good design.
Some rhymes are philosophical. Blockchain people have a mantra: not your keys, not your coins. The AI-era version is not your infrastructure, not your context. The leverage this partner gives me is durable and mine because the stack is mine. The same capability rented from a SaaS would be leverage on loan — with the company’s institutional memory as the collateral.
And one rhyme is a prediction. Today my partner mostly answers. Increasingly, agents will act — send the email, file the change, pay the invoice. The moment an agent acts on your behalf, “what did it know and when did it know it” stops being a curiosity and becomes an audit requirement — and a signed, tamper-evident log of what an agent knew and did is the primitive that answers it.
The agent layer is the point
Everything above — mirror, index, search tool — is necessary and insufficient. “Chat with your documents” was 2023’s demo. What makes this a partner is what sits on top.
The agent (Claude Code in my case, though the stack is agent-agnostic by design — that’s what MCP buys) doesn’t just query the knowledge base. It keeps persistent memory of its own: a set of Markdown files describing the system’s architecture, its invariants, and the lessons from every incident we’ve debugged together. Every session starts by reading its own runbook.
This pays off in ways that still feel slightly unreasonable. When the index broke after that laptop suspend, I didn’t debug it — I described the symptom. The agent read its runbook, checked container health, found the wedged embedder, wrote the preflight fix, and then — this is the part I love — updated its own documentation so the next session would already know. The operational knowledge lives next to the code, in plain text, maintained by the thing that uses it.
That’s the actual frontier, and it’s why I keep saying partner instead of tool: an agent that doesn’t just consume the knowledge base, but operates and improves the infrastructure that feeds it.
Build yours: the blueprint
The generalized recipe is five steps:
- Mirror every source to plain files. One-way, read-only credentials, each API through its native incremental idiom. Plain text is the universal interface — every tool you’ll ever want already speaks it.
- Normalize to Markdown. Direct conversion for pages and threads; docling for binaries. Cap pathological outputs with reference stubs.
- Index locally. Section-aware chunks, a local embedding model, a local vector DB. Incremental by content hash. Deletions must reconcile.
- Expose exactly one search tool over MCP. Filters for source, author and date. Citations mandatory — an answer without a path is a rumor.
- Give the agent memory, then give it the keys. A runbook it reads, lessons it writes back, responsibility for the stack it depends on.
Even if you build none of it, three habits transfer to any system: one timer and one atomic commit per cycle (your future debugging self says thanks); preflight health checks that fail fast instead of hanging; and a two-tier dependency policy — auto-update what’s safe, pin what can silently corrupt.
Hardware honesty: all of this runs on one laptop with 32 GB of RAM and no GPU (what local models do to your RAM). The retrieval stack costs $0/month — open-source software, openly licensed models. The agent on top is your choice: a frontier-model subscription, or fully local if your hardware and patience allow.
One non-technical step belongs in the recipe too: depending on where you work, mirroring company data — even onto a company laptop — may need a conversation with whoever owns your data policy. Have it early. “The knowledge base never leaves my machine” is a strong opening argument, and being the person who asked is part of being the person they trust to build it.
Closing
When companies talk about “AI adoption”, they usually mean buying chatbot licenses. I think it will end up meaning something else: every employee with an agent that knows their slice of the company — built close to the work, owned close to the work, citing its sources, running where the data is allowed to live.
The ingredients are sitting in front of you: your mail, your meetings, your messages, your documents. Mirror them, index them, hand them to an agent — and let it take over everything that never actually needed you.
An AI can take over the automatable half of your job. It can’t be the person who automated it. Be that person.
Then look one move ahead. The agent that answers today will act tomorrow — and the instant it does, proving what it knew and what it did stops being trivia and becomes the whole game. Making an agent knowledgeable and making it accountable turn out to be one problem attacked from two sides: AI reaching for verifiable memory, and the ledgers that always had it becoming where agents act. That convergence is the most interesting place I know to stand — and it’s where I’ve chosen to build.
Fittingly: this post was outlined, fact-checked and diagrammed with the partner it describes — it searched its own index to verify the architecture section above. If you’re thinking about giving your team AI partners, or building systems where independent parties need to trust shared data, those are the two problems I most enjoy. The links in the footer know where to find me.